Biometriai azonosító, jellemző
Az azonosítás objektuma, tárgya (pl. az ujj fodorszál szerkezete)
Nem szabad azonban keverni az azonosítás objektumát azzal, hogy az a személy melyik testrészéről származik. Pl. az ujjat többféleképpen is fel lehet használni az azonosításhoz (az azonosítás objektuma más és más)
- daktiloszkópia
- az ujj geometriája
- az ujj véredényrendszere
és mindegyik esetben
- fodorszál szerkezet
- geometria
- véredény szerkezet
A mintavételezés (enrollment, sample)
Példa: daktiloszkópia
A fodorszál szerkezetről számos módszerrel alkotnak képet, ennek legrégibb eljárása, hogy a festékezett ujjakat papírra nyomják. Ez a mintavételezés nagy az információ veszteséget jelent az elméletihez képest: a festék eltakarja a pórusokat, számos esetben a minuciák nem lesznek megkülönböztethetők (elágazás vagy megállópont) sok/kevés festék esetén számos minúcia nem lesznek látható.
A technikai megoldások adott biometriai azonosító kinyerésére. Pl. fodorszálszerkezet esetén:
- kapacitív olvasó
- optikai olvasó
- ultrahangos olvasó
- stb. minden olyan technikai megoldás, mely az ujj fodorszászerkezetéről képet alkot a további daktiloszkópiai azonosításhoz.
az objektumok összehasonlítására vonatkozó eljárások. Például fodorszálszerkezet esetén minden olyan, mely a fodorszál-szerkezeten alapul (ez a daktiloszkópiai módszer)
- minucia összehasonlítás (minucia matching)
- rajzolat összehasonlítás
- poroszkópiai összehasonlítás
Az elterjedt szóhasználat sajnos már nehezen pontosítható, emiatt van az, hogy pl. arc azonosítás esetében az azonosítás objektumát keveri a származási hellyel-a biometriai azonosító mintavételi technikájával. Például arc azonosítás történhet hőtérkép, ráncok/barázdák, geometria alapján, ez utóbbi 2D vagy 3D is lehet
Pontosítva arc esetében a biometriai azonosító jellemző
- az arc hőtérképe
- arcbőr (barázdák, ráncok)
- arc geometria
- arc geometria 2D
- arc geometria 3D
Hasonlóképpen érdemes lenne a pontosság kedvéért a számazási hely mellett mindig feltüntetni az azonosítás objektumát (a tényleges biometriai jellemzőt) minden esetben. Jó lenne, de ezen a lapon sem tesszük meg.
Az adott objektum (pl. fodorszálszerkezet) vizsgálatára vonatkozó összehasonlítási módszer (pl. minucia matching) pontosságát jelenti. Biometriai azonosításnál a pontosság statisztikai mérőszám! Míg a hagyományos azonosításnál, - pl. PIN kód - kategorikus IGEN-NEM választ kapunk, addig a biometria csak valószínűséget ad, mely 100%-nál kisebb. Ennek az az oka, hogy az összehasonlítás két objektuma (a vett minta/sample és a tárolt minta/template) eltér egymástól, nem tökéletesen egyforma. Például arc esetében a mintavételi pozizició, arckifejezés, megvilágítás, szemüveg mintavételi/sample változatosságot okoz, ugyanígy a szakáll, sérülés, öregedés is különbségeket okoz a template-nél. Ez mind azt eredményezi, hogy az azonosságnak csak valószínűsége van.Ezt fejezi ki a FAR és FRR pontosságot jellemző érték (ld. később). A FAR és FRR értékek mérési értékek, tesztelések során mérik le a gyártók, illetve a felhasználók (már amelyik képes rá, mert szaktudást és, időt és nagy költséget jelent). A teszt az időigény és a rendelkezésre álló kevés adat miatt viszonylag kis tárolt minta/template adatbázison és viszonylag kevés számú mintával/sample történik (ne feledjük: egy-egy méréshez egy-egy személy szükséges). Az így elvégzett teszteredményekből történik meg a következtetés, hogy mi történt volna, ha tízszer több energiát fordítottunk volna a tesztelésre. Tehát már maga a teszt is csak valószínűsít egy valószínű eredményt.
A biometriai azonosító jellemzővel elérhető elméleti maximális pontosság (natív pontosság)
Ez alatt az azonosítási objektum (pl. fodorszálszerkezet) szelektivitását értjük, azaz azt, hogy az mennyi személyt tud megkülönbözteni. (azt láttuk, hogy az antropometria kudarcát az okozta, hogy találtak két embert, aki között nem tudott különbséget tenni a módszer, mintegy "összekevert" két személyt. Nem tudjuk az adatokat pontosan, de ha a nyilvántartásban volt 10.000 személy, és ebből összekevert 2-t, akkor a szelektivitása 1:10.000-nél gyengébb.
Feltehetjük azt a kérdést, hogy a különböző biometriai objektumoknak mekkora a szelektivitása, vagy a natív pontossága?
A natív pontosság és az effektív pontosság közötti különbség
Hogy miért van erre szükség? Mert akkor mérés nélkül is lehet elképzelésünk egy módszer képességeiről: az elméleti határnál biztosan gyengébb. Mert az elméleti pontosság egy elméleti pontos mintavételezésrő és egy elméleti pontos összehasonlító algoritmusról szól. Az eltérés lehetséges okait a következőkben az ujjnyomatazonosítással illusztráljuk.
Az azonosítási objektum mintavételezése soránAz első információveszteségi szint. A mintavételi technika (pl. felbontás, hibákra való érzéketlenség, stb. ) információveszteséget okoz, ezáltal negatívan befolyásolja a pontosságot: a feature extraction gyengébb eredményét okozza.
Azonosítási objektum feldolgozása (feature extraction) soránA második információveszteségi szintet a minuciák felismerése/nem felismerése jelenti: míg az elméleti pontosság egy szakértőt vesz figyelembe - emberi szem - addig a "gépi szem" (feature extraction) rosszabbul lát: amit szabad szemmel jól látunk, az "elektronikus szem"rosszabbul lát:
nem vesz észre információt, vagy olyat "képzel", ami nincs is a képen.
A mintavételezés technikai megoldásai ezeket a klasszikus hibákat egyre jobban kiküszöbölik: (az elméleti pontosság arra vonatkozik, hogy mit lát a szem az ujjon. A gépi megoldások ugyan képet készítenek, de nem úgy, ahogy a szem, hanem közvetett módon: mérnek valamit, amiből képet állítanak elő: pl. hőmérsékletet (thermo olvasó), fényelnyelést (abszorpciós optikai olvasó), elektromos jellemzőt (kapacitív olvasó), stb. A módszerek érzékenyek azonban olyan bőr minőségekre, hibákra, mint pl. száraz bőr, nedves bőr, lekopott bőrfelület, emiatt olyan felületről, amit szabad szemmel jól látunk, az "elektronikus szem" rosszul lát.
Azonosítási objektumok összehasonlítása (matching) soránAz elméleti összehasonlító algoritmusokkal (Ld. hagyományos daktiloszkópiai szakvélemény) ellentétben a gyakorlati algoritmusok számos egyszerűsítést tesznek, így az elméletihez képest veszítenek - nagyságrendekkel! - a pontosságból. Példa:
maradva a minucia matching algoritmusoknál, az elméleti pontossághoz - később látható lesz, a Galton pontok tartoznak, melyekből 10-15 félét is megkülönböztetnek. Ennek alapján számolták ki a pontosságot. Azonban a matching algoritmusok csak kétféle minúciát ismernek: megállópont, elágazási pont. Nyilvánvaló, hogy ha 10 egyedi jellemzőt alkalmazunk, akkor a pontosságunk nagyságrendekkel nagyobb lesz. Ugyanezen körbe tartozik a minuciák egymáshoz viszonyított helyzete: az elméleti pontosságnál a helyzethez fodorszál metszet távolságot használnak, (ez állandó, nem befolyásolja a kép torzítása, nagyítás, kicsinyítés. A számítógépesnél fizikai távolságot használnak, így ha a képet pl. felnagyítjuk, akkor nem lehet azonosítani. És nem is kell felnagyítani, elég, ha torz a kép: pl. nagyon rányojuk az ujjunkat az olvasóra, akkor szétterül a bőr, és a minuciák távolsága kisebb/nagyobb lesz mintavételenként.
Látjuk tehát, hogy az elméleti pontosság és a matchig (számítógépes) pontosság szükségszerűen különbözik. Tehát van a natív pontosság, és a biometriai azonosítási módszer (számítógépes) pontossága.
Számos gyártó próbál hamis utalásokkal olyan képzetet okozni bennünk, hogy a natív pontosságra hivatkozva pontosnak állítja az általa kínált berendezést. Ez "csúsztatás", enyhén fogalmazva. Egyszóval: tudnunk kell, hogy a natív pontosságnál mind berendezés gyengébb.
Más biometriai jellemzők natív pontossága
A daktiloszkópián, a genetika rendelkezik igazán meggyőző, és óriási statisztikai adatokon alapuló pontossági számításokkal.
Sajnos, a többi módszer a daktiloszkópiához képest gyerekcipőben jár, még nem is lehetnek olyan statisztikai adatai, mint a daktiloszkópiának.
Akkor mégis mennyi? Mindegyikről az tudni, hogy véletlenszerűen alakulnak ki, és ez adja a változatosságukat. (Ilyen a fodorszál szerkezet is, fenotype). De ha arról tudjuk, hogy mennyi az elméleti pontosság, akkor miért nem tudjuk a többiről? Vagy másképpen feltéve a kérdést, miért tudjuk a fodorszálszerkezetről? Erre már könnyebb válaszolni!
Az igény megvolt rá, fejlett elektonikai technikai eszközöket nem igényelt, sőt: papír kellett csak és festék. Előzményei megvoltak, időszámítás előttről is, ld. daktiloszkópia története. Szükségszerűen a terjedése az elméleti megalapozottságra fokozott igényt termtett, és kiváncsiság is dolgozott. Szinte az egész világ kutatta a témát, hiszen a műszaki technikai fejlettségi színvonala egy-egy országnak nem volt akadály. Hatalmas mennyiségű adat állt már rendelkezésre, melyekből statisztikusan elegendő információt lehetett összegyűjteni az elemzésekhez. (Tulajdonképpen matematikai megalapozottság nélkül, bízva a megérzésekben, kezdték el gyűjteni a nyomatlapokat. A tudományosság, a statisztikai elemzések nem megalapozták a daktiloszkópia bevezetését, hanem utólagosan igazolták.
Ma azt várnánk el egy biometriai módszer bevezetése előtt, hogy igazolják tudományosan, hogy mi várható tőle, és akkor bevezetjük. De akkor honnan lesz elegendően sok adatunk, hogy bevezessük?
Ez a paradox helyzet az, ami miatt a daktiloszkópia tudományos megalapozottság szempontjából még jóideig behozhatatlan előnnyel rendelkezik. Éppen ezért a többi biometriai azonosítás pontosságát indirekt módon, a daktoloszkópiával összehasonlítva lehet meghatározni, natív pontosságuk nem ismert.A daktiloszkópiával is akadnak problémák, de azokról mindig bebizonyosodott, hogy emberi-szakértői mulasztás-tévedés okozta. De mi történne, ha pl. találnánk két egyforma irisz kódot? Az visszamenőlegesen is katasztrófa lenne, az irisz azonosítást pedig a süllyesztőbe küldené. (Az irisz azonosítás pontosságára vannak számítások, mégpedig igen magas:1:10-15 milliárd)Emlékezzünk a Bertillon féle antropometriai rendszerre: a csődjét elsősorban az okozta, hogy nem azt kaptuk tőle, amit vártunk, hanem azt, amiben bíztunk.
Így eljutottunk a pontosság egy más megközelítéséhez: ha egy biometriai módszert akarunk kiválasztani, akkor a pontosság mértéke mellett a bizonyossága is számít.
A jelenlegi módszerek pontossága csak a jelenlegi feltételek (eddigi mérési, gyakorlati tapasztalatok) mellett értelmezhető. Ezekből következtetni, hogy más feltételek között (pl. ezerszer akkora adatbázison) mi várható, inkább hit kérdése.
Biometriai módszerek összehasonlítása (Benchmark)
Natív pontosság alapján a módszereket nem tudjuk összevetni a rendelkezésre álló adatok hiánya miatt.A FAR és FRR értékek alapján lehet összehasonlítani különböző biometriai azonosító megoldásokat!, nem a biometriai azonosítási objektumok alapján!
Ez pedig a gyártók által kínált eszközök összehasonlítását jelenti, a biometriai jellemzőtől függetlenül. Emiatt ezeken az oldalakon nem fog az olvasó találkozni ilyen összehasonlító táblázattal. Azt javasoljuk, hogy ezeket az általános táblázatokat óvatosan kezelje. Közhelyeket mondanak: pl. a DNS a legpontosabb, az irisz a második, az ujj a harmadik, stb.
Még csak nem is tájékoztatnak arról, hogy az alkalmazásunk követelményrendszerét melyik biometria azonosító megoldás elégíti ki.
Multimodal biometrics (többféle biometriai objektum együttes alkalmazása
Amikor egy biometriai objektum szelektivitása nem elegendő (vagy a matching nem elég hatásos), akkor társítják egy másik biometriai jellemzővel is az azonosítást. Ilyen például amikor hangfelismerést kiegészítik tudásbázisú azonosítással: pl. kérdésekre kell válaszolni. Hasonlóan kiegészíthető az ujjnyomatazonosítás egy következő ujjal. Ez is multimódusú, de csak duplikált adott módon belül.
Másik oka a társításnak, pl. a hamisítás felismerése. Például az arc geometriájának azonosítását kiegészítik pupilla reakció azonosítással (szükül, mozog adott irányba).
Harmadik oka a társatásnak az, hogy alternatív lehetőséget biztosítson arra az esetre, ha az elsődleges biometriai objektum mintavétele nem lehetséges ld. FTA és FTE (Failure to Acquire, Failure to Enroll) . Például ha az adott ujj túlságosan kopott, akkor egy másik ujj, vagy ha mindegyik kopott, akkor irisz.)
Near infrared light (infra közeli fény)
A következő ábra a Wikipedia-ból származik (EM_spectrum.svg, Philip Ronan). Azt mutatja, hogy a az elektromágneses hullámtartományt milyen szakaszokra osztják fel:
Multispectral imaging (több hullámhosszúságú fény alkalmazása)
Különböző hullámhosszúságú fénnyel történő megvilágítással nyert több képből állítják elő a biometriai minta képét.
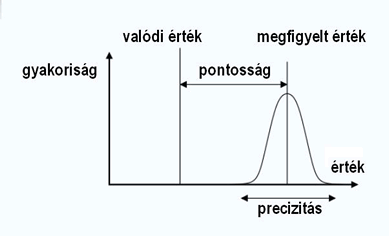
Pontosság és precizitás (balra: pontos, de nem precíz, jobbra: precíz, de pontatlan)


Alapfogalmak
Failure to Acquire (Failure to capture)
Bizonyos esetekben a személytől nem lehet biometriai mintát venni - noha már az enrollmentnél sikerült, - mert pl. az ujja kopott lett, vagy kiszáradt, vagy levágta, vagy ... Ez a biometriai adat sérülékenységére, vagy a mintavevő érzékenységére (hibatűrés) jellemző adat
Az előzőhöz hasonló. Azzal a különbséggel, hogy ez már inkább egy stabilabb állapotot jelez: a személy biometriai szempontból nem alkalmas ezzel a biometriával
False Acceptance Rate (False Match Rate FMR, type II error)
Hibás elfogadás aránya, azaz az azonosítás téves, mert hibásan mondott egyezőséget. %-ban, vagy 10 hatványával fejezik ki (pl. FAR=0,1%)
False Rejection Rate FRR (False non-match rate FNMR, de ez nem tartalmazza azokat, akiket nem lehetett felvenni az adatbázisba, type I error, True Acceptance Rate TAR negáltja)
Hibás visszautasítás aránya, azaz a téves azonosítások aránya, mert a rendszer nem tudta azonosítani azt, akit kellett volna. Százalékban fejezik ki.
az azonosító rendszerek egy-egy összehasonlítás során a keresett nyomatot összeveti az adatbázisban levőkkel, egyenként egy hasonlósági számot képez (score), aztán sorbaállítja az eredményt a csökkenő score szerint, és döntést hoz, hogy az első helyen levő találat-e vagy sem.
alapján döntenek a találatról: ha az első score érték alacsonyabb a küszöbértéknél, akkor nincs találat (NOHIT), ha magasabb, akkor van találat (HIT).A küszöbérték állítható.
AFIS rendszerek általában kijelzik az első 5-10 eredményt az ún. kandidátus listán (Candidate list), melyet egy ujjnyomatszakértő ellenőriz végig: a döntést a találatról ő hozza meg. Az AFIS rendszereknél nyomazonosításnál nincs automatikus döntés!
nak nevezzük a bűncselekmény helyszínén rögzített nyomot,
nak pedig a nyomatlapkészítéskor festékezési eljárással, vagy élő ujjnyomolvasóval rögzített lenyomatot.)
a biometriai minta, amit az azonosításkor vesznek fel
az a már korábban felvett, ellenőrzött sample, melyet a további összehasonlításokkor referenciaként fognak használni
HIT score hisztogram, NOHIT score hisztogram
: képzeljünk el egy beléptető alkalmazást, ahol az adatbázisban van pl. 1000 személy, - aki jogosult egy ajtón bejutni (Genuine). Készítsünk egy mérést, melyben az 1000 jogosult megpróbál bejutni az ajtón, és feljegyezzük mindegyik score értékét.. Ezekből kiválsztjuk azt az 1000 értéket, ami az adott személy adatbázisban levő ujjának összehasonlítására kapott.
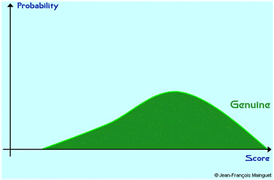
A vízszintes tengelyen ábrázoljuk, hogy egy-egy score értéket hány Genuine ért el.
Egy másik grafikonon ábrázoljuk azt, hogy a többi adatbázisban levő ujjal történő összevetésnél hány pontot kapott az illető (ha leszámítjuk, hogy benne van az ujja, akkor ez esetben ő jogosulatlan (Impostor)
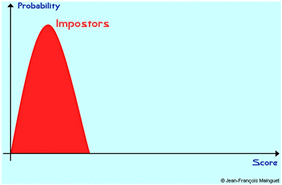
A két hisztogramot egy koordinátarendszerben ábrázolva
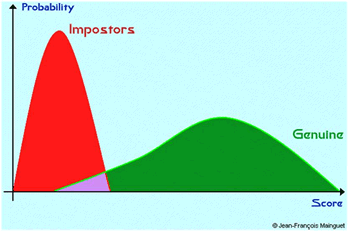
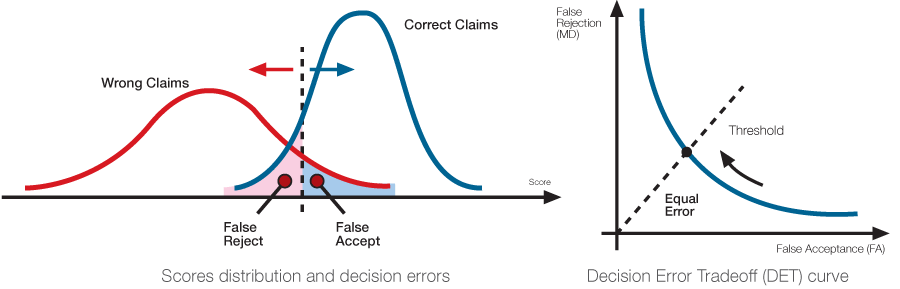
azt látjuk, hogy a két hisztogramnak van közös része. Van egy score értékünk, mely felett van az összes genuine, és van egy score értékünk, mely alatt van az összes impostor. A két score érték között pedig vegyesen van genuine is és impostor is.
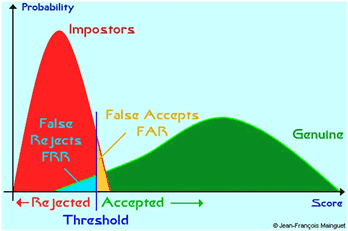
A két érték között mit válasszunk küszöbértéknek? Bármit is választunk, azt tudjuk: azt a genuine-t, amelyik így a küszöb alatt lesz, azt nem engedjük be az ajtón (FRR, azaz hibásan visszautasítjuk), és az az impostor, amelyik a küszöb felett lesz, az jogosulatlanul bejut, mert tévesen úgy viselkedtünk vele, mintha genuine lenne (FAR hibás elfogadás)
A következő ábrákon csak a kritikus tartományra koncentrálunk. A vízszintes tengelyen van két pont: aholaz imposztor görbéje metszi a tengelyt (ez az a score érték, melynél és felette a FRR=1 lesz (és FAR=0), illetve a genuine görbe metszéspontja, melynél és alatta a FAR=1 lesz (és FRR=0).
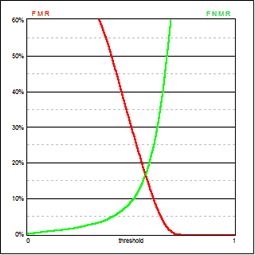
Error Equal Rate a két görbe metszéspontja, az az érték, melynél a FAR és az FRR ugyanazt az értéket veszi fel (a hiba azonos).
Az eddigiekből azt látjuk, hogy a küszöbérték változtatásával változtatni tudjuk a FAR és FRR értékeket egyszerre, külön-külön azonban nem.
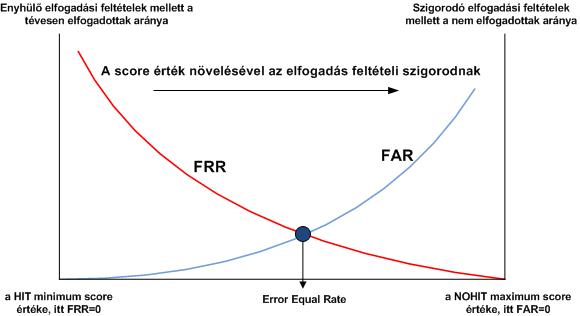
Receiver Operating Characteristic a FAR és FRR értékeket mutatja a threshold függvényében.
Az ábrából leolvasható, hogy ha változtatjuk a küszöbértéket (a görbén jelzett pontok mutatják színkóddal), akkor milyen értéket vesz fel a FAR és az FRR.
Például a thresholddal beállítunk egy konkrét FAR-t, akkor a ROC görbe megmutatja, hogy ehhez milyen FRR érték adódik.
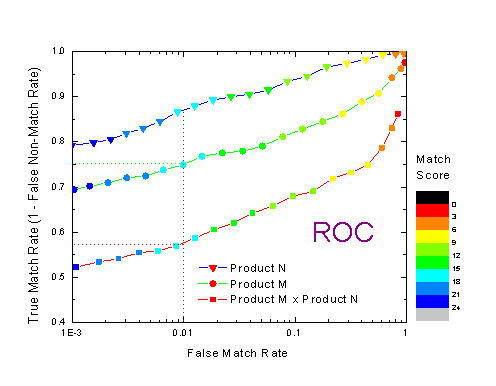
A Detection Error Trade-off diagram ugyanazokból az adatokból készül, mit a ROC görbe. A ROC-ból kiolvashatjuk gyorsan, hogy a találati arány (True Match Rate=(1-False Non-Match Rate)) hogyan növekszik, ha az azonosítás szigorúságán enyhítünk.
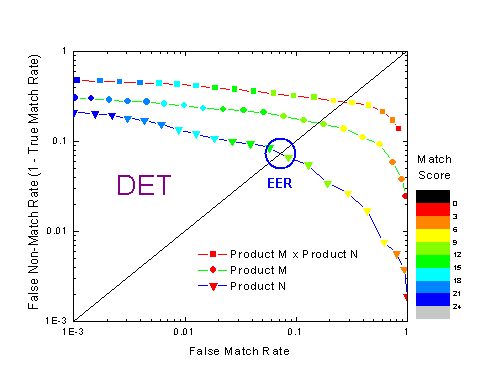
És ugyanaz, másképp: inkább magyarázó, demonstrációs jellegű. Azt mutatja, hogy egy-egy alkalmazásnál hogyan szokták az ERR ponttól eltolni az azonosító rendszer munkapontját. (A munkapont az Error Detection Rate, mely nem azonos az EER ponttal. )
Végezetül még néhány alapfogalom az alkalmazás típusokra:
Verification, (1:1, vagy one-to-one) comparison, ahol ismert személyről kell megállapítani, hogy szerepel-e az adatbázisban
Closed-set Identification, 1:N, vagy one-to-many comparison, ahol egy személyről (akinek egyébként szerepelnie kellene) akarjuk megtudni, hogy ténylegesen kicsoda. Eredményes az identification, ha a keresett személy egy K hosszú kandidátuslistán szerepel (tipikusan: beléptetésnél K=1).
Open-set Identification, 1:N comparison, ahol választ várunk arra, hogy egy ismeretlen személy szerepel-e egyáltalán az adatbázisban. Tipikus alkalmazás pl. a körözöttek listájában történő ellenőrzés, vagy AFIS nyomazonosítás. Eredményes az azonosítás, ha a keresett egy K hosszú kandidátuslistán szerepel.(Az ilyen célú rendszerek jellemzésére legtöbbször a TAR-FAR ROC görbét használják.)